




UNIST site map
- Admissions
-
Academics
- Colleges and Schools
-
Academic Affairs
- Academic Calendar
- Academic Curriculum
- Requirements for Graduation
- Browse Open Courses
- Undergraduate Administration
-
Graduate Academic Affairs
- Tuition Fee Payment
- Academic Leave of Absence/ Academic Return
- Voluntary Withdrawal/ Expulsion
- Change of Major
- Change of Degree Program/ Dropping of Degree Program
- Class Period/ Attendance Period/ Academic Year・Semester
- Course Registration
- Course Drop
- Attendance/ Grade/ Exam
- Credit Transfer/ Credit Carryover
- Academic Forms
- Education Support
-
Research/Industry
- Research Aims
- Research Findings
- Researcher Search
-
Research Organizations
- UNIST Multi-Interdisciplinary Institute
- IBS Research Groups
-
UNIST Labs
- Department of Mechanical Engineering
- School of Energy and Chemical Engineering
- Department of Civil
- Department of Materials Science and Engineering
- Department of Nuclear Engineering
- Department of Industrial Engineering
- Department of Design
- Department of Biomedical Engineering
- Department of Biological Sciences
- Department of Electrical Engineering
- Department of Computer Science and Engineering
- Department of Mathematical Sciences
- Department of Chemistry
- Department of Physics
- School of Business Administration
- Graduate School of Carbon Neutrality
- Graduate School of Artificial Intelligence
- Research Support
- University-Industry Relations
- Campus Life
- News Center
- About UNIST
-
etc
- UNIST Bulletin
- Work-Life Balance Support System
- UNIST Gender Equality Plan
- Faculty Invitation for Tenure Track
- Faculty Invitation for Non-Tenure Track
- Board Meeting Minutes
- University Council Meeting Minutes
- Administrative Service Charter
- Privacy Policy
- Copyright Policy
- Rejection of Unauthorized Email Collection
- Operation and Management Policy for Video Information Processing Devices
- Information Disclosure


Connection Points of Knowledge, Everything About UNIST
Try searching.
Recommended search terms








- portal
- U Academics Innovation Center
- Leadership Center
- Dormitory
- Academic Information Center
- International Students Support
- Browse Open Courses
- Course Registration
- Graduation Requirements for Graduation
- Academic Leave of Absence/ Academic Return
- Military Service
- Certificate Issuance
- Academic Calendar
- Scholarships
- Campus Map
- Campus Life Guidebook
- Health Care Center
- Human Rights Center
- portal
- Job Opening
- Announcement for Bid
- UNIST AI Services
- UNIST Daycare Center
- Sports Center
- UI Downloads
- Announcement
- Recruitment of Professors (Non-tenure)
- Faculty Invitation for Tenure Track
- UNIST Academic Information Center
- Office of Research Facilities and Training
- Office of Research Affairs
- Rule Management System
- Academic Calendar
![]()
![]()
This is a collection of menus necessary for UNIST students .
students
- portal
- U Academics Innovation Center
- Leadership Center
- Dormitory
- Academic Information Center
- International Students Support
- Browse Open Courses
- Course Registration
- Graduation Requirements for Graduation
- Academic Leave of Absence/ Academic Return
- Military Service
- Certificate Issuance
- Academic Calendar
- Scholarships
- Campus Map
- Campus Life Guidebook
- Health Care Center
- Human Rights Center
![]()
![]()
This is a collection of menus necessary for prospective UNIST Students .
prospective Students
![]()
![]()
This is a collection of menus necessary for UNIST Faculty & Staff .
Faculty & Staff
- portal
- Job Opening
- Announcement for Bid
- UNIST AI Services
- UNIST Daycare Center
- Sports Center
- UI Downloads
- Announcement
- Recruitment of Professors (Non-tenure)
- Faculty Invitation for Tenure Track
- UNIST Academic Information Center
- Office of Research Facilities and Training
- Office of Research Affairs
- Rule Management System
- Academic Calendar


NEWS CENTER
Discover not only Research Findings and event news, but also the diverse facets of UNIST presented by reporters and writers.
News Center

UNIST News
UNIST Demonstrates Global Competitiveness in Reinforcement Learning with Three Papers Accepted to ICLR 2026
Three papers by Professor Seungyul Han's team have been accepted for publication at the International Conference on Learning Representations (ICLR 2026).
- Research
- JooHyeon Heo
- 2026.04.27
- 255

UNIST has demonstrated strong international competitiveness in reinforcement learning, a core technology for physical AI, with three papers by Professor Seungyul Han’s research group from the Graduate School of Artificial Intelligence accepted to the International Conference on Learning Representations (ICLR 2026), held in Rio de Janeiro, Brazil, from April 23 to 27, 2026.
ICLR, alongside NeurIPS and ICML, is widely regarded as one of the world’s leading artificial intelligence conferences. This year, approximately 5,300 papers—about 27% of more than 19,000 submissions—were accepted, making the selection of three papers from a single research group a notable achievement.
The accepted studies address key challenges in reinforcement learning, where AI systems learn optimal actions through interaction with their environment—an approach essential for applications, such as robotics and autonomous systems operating in complex, real-world conditions.
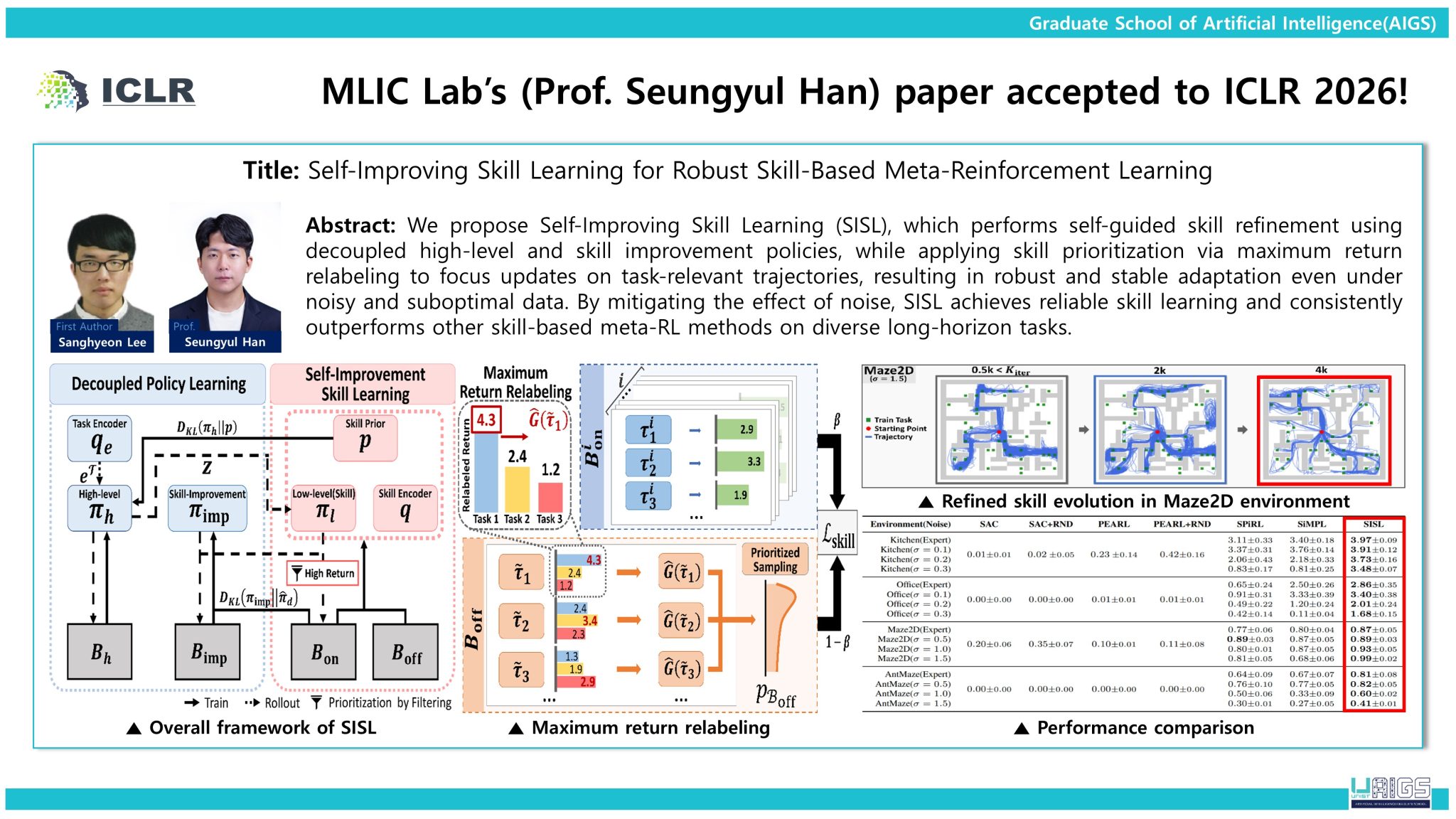
The first study proposes Self-Improving Skill Learning (SISL), a method designed to enable robust learning from noisy offline data. By decomposing long-horizon tasks into reusable skills and refining them through prioritized updates, SISL mitigates the impact of imperfect data and supports stable adaptation across complex tasks.
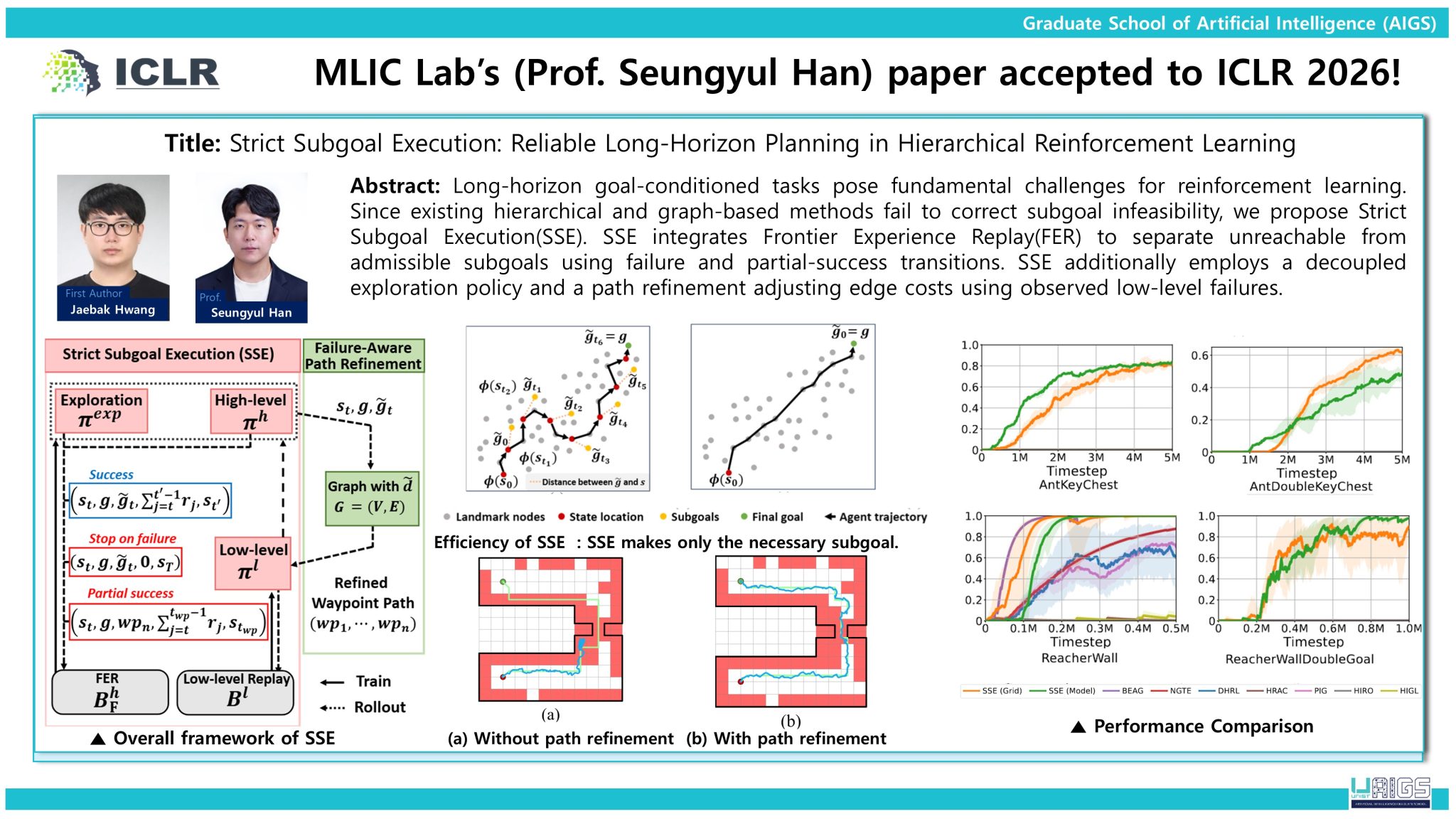
The second study introduces Strict Subgoal Execution (SSE), which improves long-horizon planning by distinguishing feasible subgoals from unreachable ones. By leveraging past failures and partial successes, the method enhances planning efficiency and increases overall task reliability in goal-conditioned environments.
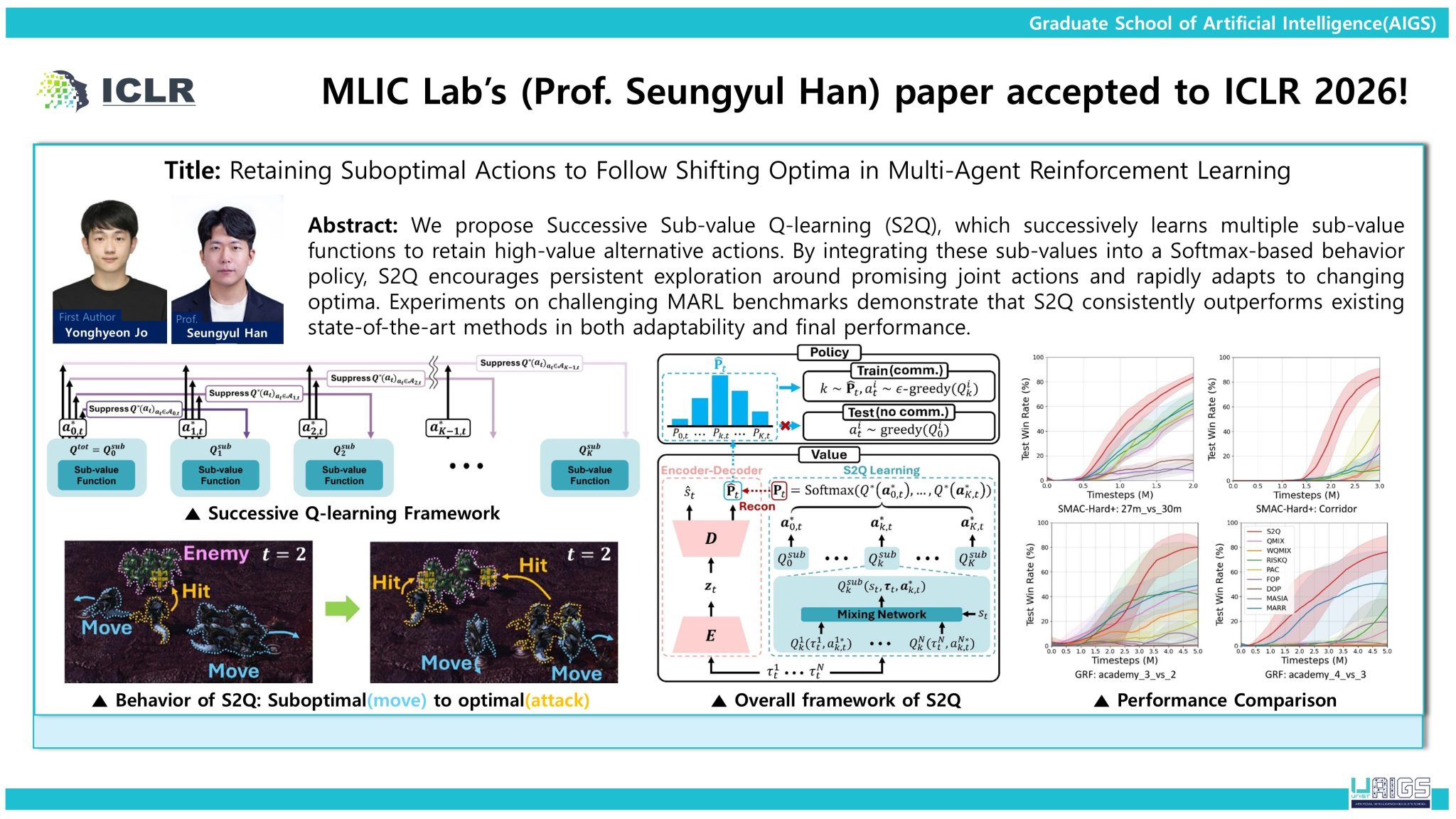
The third study presents Successive Sub-value Q-learning (S2Q), a framework for multi-agent reinforcement learning (MARL) that retains multiple high-value action candidates. This approach enables agents to adapt more effectively in dynamic environments where optimal strategies shift over time, improving both coordination and overall performance.
The research was led by Sanghyun Lee, Jaebak Hwang, and Yonghyeon Cho as first authors, respectively, and supported by programs funded by the Ministry of Science and ICT (MSIT) and the National Research Foundation of Korea (NRF).
Professor Han said, “Our research demonstrates that reinforcement learning can be applied more reliably in environments with limited data and uncertainty, with strong potential for applications in autonomous driving, robotics, and smart manufacturing.”
Journal Reference
[1] Sanghyeon Lee, Sangjun Bae, Yisak Park, Seungyul Han, "Self-Improving Skill Learning for Robust Skill-based Meta-Reinforcement Learning," ICLR 2026.
[2] Jaebak Hwang, Sanghyeon Lee, Jeongmo Kim, Seungyul Han, "Strict Subgoal Execution: Reliable Long-Horizon Planning in Hierarchical Reinforcement Learning," ICLR 2026.
[3] Yonghyeon Jo, Sunwoo Lee, Seungyul Han, "Retaining Suboptimal Actions to Follow Shifting Optima in Multi-Agent Reinforcement Learning," ICLR 2026.
Related Links
Related Photo






-
New Study Unveils AI Technique Enabling Robots to Adapt to Unseen Tasks with Greater Flexibility
-
Simulating Wolf Pack Attacks to Strengthen AI Collaboration and Resilience
-
New EPQ Technology Boosts Accuracy of AI Decision-Making in Data-Scarce Environments
-
Breakthrough QD Display Technology Achieves 4,000 PPI Resolution — Ideal for XR Glasses



